

¿Por qué es necesaria la clusterización de keywords?
Las búsquedas en Google pueden ser de lo más variadas, también cuando se trata de lo que consideraríamos un mismo concepto e incluso una misma búsqueda. Por ejemplo, en caso de querer comprar una camiseta negra podría buscar: «camiseta negra», «camisetas negras», «comprar camisetas negras», «camisetas de color negro», «camiseta manga corta negra», «camiseta verano negra» y así un larguísimo etcétera.
Es por esta razón que, al analizar el origen de las variaciones en impresiones o clics en una página específica según de la keyword de la que procedan, es necesario realizar previamente una agrupación o clusterización de palabras clave. Estas palabras clave, después de todo, forman parte de un concepto más amplio y general. En el ejemplo anterior, este concepto podría ser simplemente «camiseta negra» o, de manera más general, «camiseta».
En caso de no llevar a cabo esta segmentación en grupos, solo se podría estudiar la evolución de las búsquedas, los clics o las impresiones de keywords que, por separado, nos darían un resultado poco útil desde un punto de vista práctico. Por ejemplo, si vemos que bajan las impresiones de “camisetas negras” nos puede llevar a pensar que se busca menos este concepto. Sin embargo, podría darse a la vez que suben las de “camisetas de color negro”. Lo que nos habría hecho llegar a una conclusión equivocada.
Cabe señalar que la tarea anterior es difícil por la cantidad de búsquedas que se pueden hacer durante un día en un buscador (y la diversidad en las que éstas son googleadas, por ejemplo). Las soluciones a dicho problema podrían enfocarse de muchas maneras…
¿Cómo podríamos conseguir estos clusters de keywords?
1. Crear un condicional mediante expresiones regulares que considerara todos los posibles casos.
Aunque sería posible, llevaría a destinar muchos recursos y los resultados podrían no ser satisfactorios por la dificultad de contemplar todas las casuísticas posibles.
2. Utilizar algún algoritmo de aprendizaje automático que permite una clusterización en distintos grupos de las keywords.
El proceso consiste en tener una base de datos con una columna de keywords para, posteriormente, poder sacar la raíz de dichas keywords. Luego se vectorizan estas raíces y se aplica un algoritmo no supervisado de clusterización, K-Means, por ejemplo.
El algoritmo crea los clusters minimizando el error agregado de los grupos en cada iteración.
Cuantos más clusters, más difícil será la interpretación pero menor será dicho error (error cuadrático medio o MSE por sus siglas en inglés). Es por este motivo por el que se utiliza la regla del codo y se analizan varios posibles codos para finalmente quedarnos con el que resuelva mejor el problema). Una vez se tienen los clusters se etiquetan con un nombre representativo.
Este método no está libre de problemas: no consigue clasificar la totalidad de las keywords, puede haber problemas con el Stemming, con el etiquetaje, con los sinónimos o con palabras parecidas pero conceptualmente muy distintas… Además, rara vez consigue clasificar la totalidad de las keywords.
3. Obligar a una herramienta avanzada de procesamiento de lenguaje natural (en este caso Chat GPT) a hacer la propia clasificación.
Si bien no es una solución exenta de problemas (es costosa en términos monetarios y el tiempo de computación es más alto), se consiguen resultados más satisfactorios que en los otros dos casos anteriores.
¿Cómo conseguimos la clusterización de keywords con Chat GPT?
Para llevar a cabo la clusterización de keywords utilizaremos la API de OpenAI (aquí la documentación). Con ella se fijará el modelo y los parámetros que se utilizarán. En este punto se pueden seguir dos enfoques: únicamente utilizar Chat GPT 3.5 o usar también Chat GPT 4 (dependiendo de lo que estemos dispuestos a gastar). En ambos casos el funcionamiento se basa en la clusterización por lotes de keywords (de 50 en 50 o de 100 en 100, por ejemplo).
¿Cuál es el motivo de hacerlo de este modo? Cualquier modelo de Chat GPT tiene una ventana de contexto finita (que se puede ver aquí). Si bien es verdad que las nuevas versiones amplían esta ventana de contexto y mejoran el rendimiento, la realidad es que se observa un empeoramiento de la calidad obtenida a medida que ampliamos la cantidad de tokens usados. Es decir, incluso aunque le pudiéramos pasar 10.000 keywords de golpe, los resultados seguramente serían del todo deficientes.
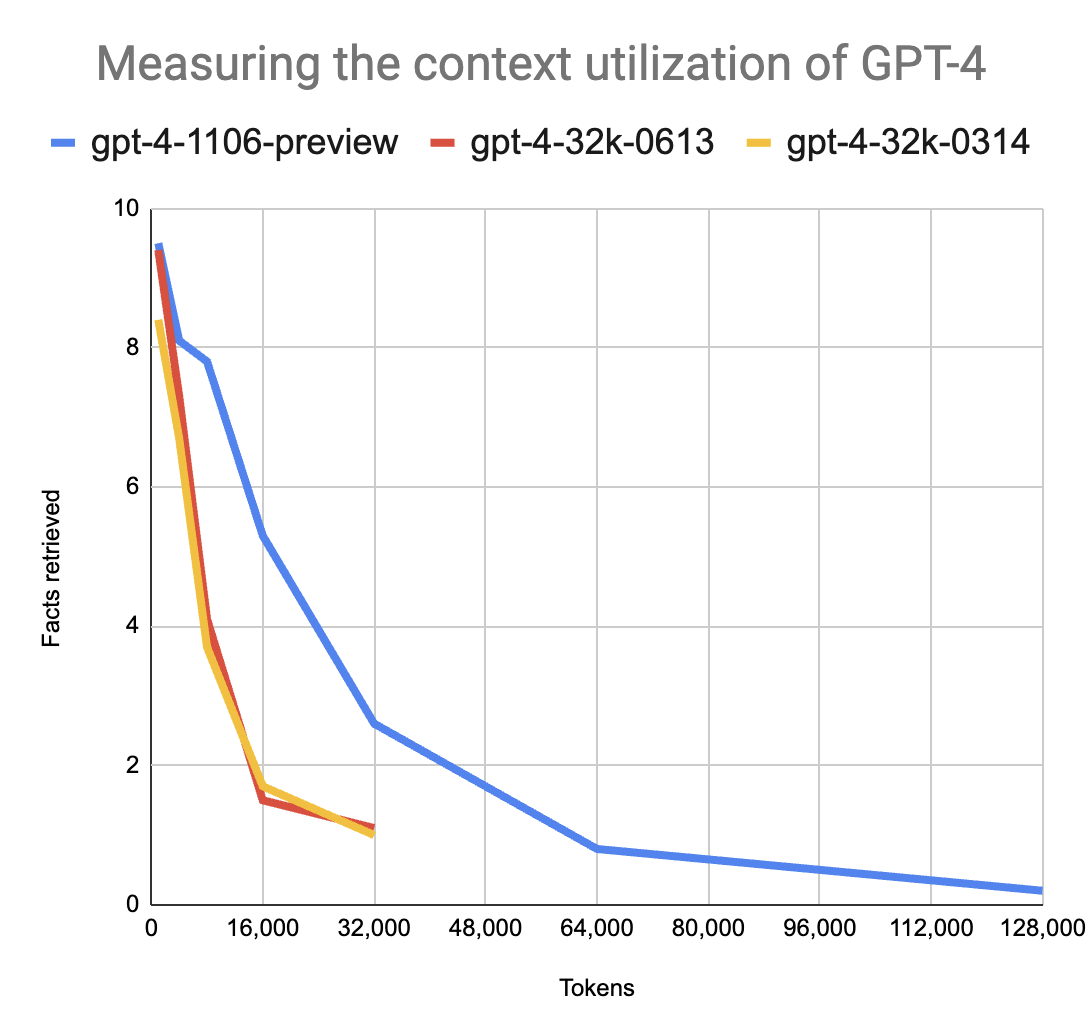
A partir de aquí, y como acabo de comentar, podríamos usar una o ambas versiones. Ambas técnicas difieren un poco entre sí:
1. Usando únicamente Chat GPT 3.5
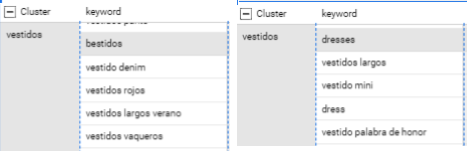
Este es el enfoque más barato pero tiene más fallos. Además, necesita que le pasen unas categorías predefinidas de antemano. En caso de que se buscara que sea el mismo el que cree las nuevas categorías, crearía muchas más de las que debería y algunas son prescindibles ya que se engloban en otras (p.e. “vestido verde”, “vestido verano” y “vestido sin mangas” iría dentro de la categoría “vestidos”). Los pasos que se seguirán serán los siguientes:
Paso 1. La preparación:
Partimos de un conjunto de keywords y un conjunto de grupos de categorías predefinido por nosotros con anterioridad. Si es un proceso que se lanza cada día, habría que tener en cuenta que algunas de las keywords de hoy ya se clasificaron algún otro día y que, por tanto, no es necesario que se vuelvan a clasificar (además, así evitamos problemas de consistencia en la clasificación de una misma keyword).
Paso 2. La clusterización:
Mediante un loop pasamos las keywords en lotes y le pedimos a Chat GPT que nos devuelva las keywords clasificadas en formato JSON. Aquí, el prompt (el input con las instrucciones que le insertamos) es importante. Os dejo un artículo que habla de ello y pone encima de la mesa 26 reglas probadas para mejorar tus prompts (también podéis encontrar algunos consejos en la página oficial de OpenAI).
Hay que tener en cuenta que en cada interacción del loop Chat GPT puede fallar por tres vías:
- Porque no clasifique todas las palabras,
- Porque no clasifique en los grupos de las categorías generales pasadas en el input las keywords,
- Porque falle (generalmente porque devuelve el JSON en un formato incorrecto o porque corta el JSON).
En estos casos se debe dar un margen de reintentos para esa misma iteración. En cada reintento se le debe pasar las keywords en un orden diferente, ya que esto mejora sustancialmente los resultados. Si una vez hechos estos intentos sigue habiendo problemas, las keywords no clasificadas o mal clasificadas se guardarán para ser utilizadas en el siguiente paso. Por tanto, al final de este segundo paso debemos tener dos listas, la lista de keywords bien clasificadas y la lista de keywords mal clasificadas.
Paso 3. La repesca:
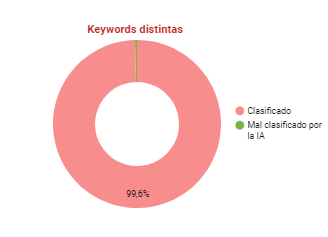
En el paso 3 intentaremos repescar las keywords mal clasificadas o no clasificadas con otro loop y mezclando las keywords otra vez. Si en este paso no se consigue una buena clasificación de alguna de las keywords, se marcarán como que no ha sido posible clasificarlas (tiende a no llegar al 0.5% del total). En nuestra prueba, lanzamos 430.000 keywords en 9 días. Algo menos de 2000 no se consiguieron clasificar:
2. Usando Chat GPT 3.5 con refinamiento de Chat GPT 4
Este es un enfoque algo más caro pero cuyos resultados son, en principio, más ajustados (y sin necesidad de inventarnos las categorías de antemano). Veamos en qué difieren los pasos a la primera metodología
Paso 1. La preparación:
Cambia el primer día porque le debemos obtener las categorías generales. Este primer día únicamente tendremos un listado de keywords. Y sacaremos las categorías en el paso siguiente. A partir del segundo día ya tendremos las categorías, sin embargo, en el segundo paso volveremos a revisar que no haya categorías nuevas (esto nos permitirá detectar categorías emergentes).
Paso 2. La clusterización:
A diferencia del caso anterior, primero sacamos las categorías nuevas vía GPT 3.5 (pongamos que obtenemos 250). Las agrupamos en GPT 4 (se reducen a 100). Posteriormente, y al igual que hacíamos en el caso anterior, lanzamos las keywords para que GPT 3.5 nos las clasifique.
Paso 3. La repesca:
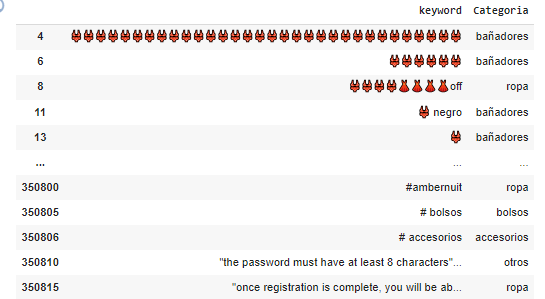
En el último paso, intentaremos repescar las keywords mal clasificadas o no clasificadas con otro loop y mezclando las keywords otra vez. Pero en este caso lo haremos con Chat GPT 4. En general el resultado es satisfactorio y se clasifican la totalidad de keywords. El resultado:
¿Pero cómo se integraría este flujo?
Veamos un ejemplo a través de este esquema funcional de Google Cloud:
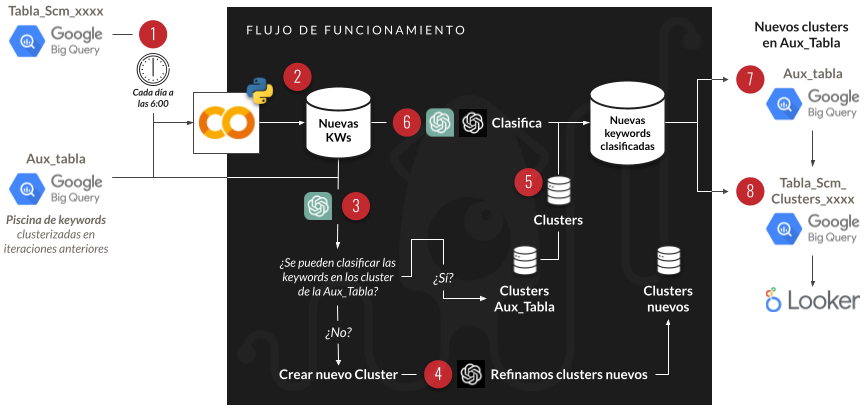
El funcionamiento sería como sigue:
- El funcionamiento del proyecto tirará de dos bases de datos:
- Tabla de GSC
- Tabla auxiliar en la que se irán guardando las equivalencias de keywords diferentes y clusters (esta tabla irá creciendo día a día en función de las keywords nuevas que no se repitan).
- Para el día X nos quedaremos con las keywords con las que no se encuentre equivalencia en la tabla auxiliar. Esto permitirá:
- Reducir la volatilidad.
- Reducir los costes.
- Reducir el tiempo empleado.
- Con Chat GPT 3.5-turbo (precio desde 0.001$/1k tokens) sacaremos las categorías (si estas no están ya contempladas en nuestra tabla auxiliar) en las que deberían clasificarse las keywords del día.
- Con Chat GPT 4 (precio desde 0.03$/1k tokens ) refinaremos el proceso y agruparemos estas primeras categorías (pasando de >230 a 50-70 categorías).
- Se unirán las dos listas en Clusters.
- Con Chat GPT 3.5-turbo clasificamos las keywords en este listado de Clusters. Se intentará impedir que:
- No clasifique todas las keywords (relanzando si se deja alguna).
- Se invente keywords nuevas (relanzado hasta un límite de 5 veces y utilizando Chat GPT 4 al final para todas aquellas keywords clasificada en categorías no presentes en el listado de categorías).
- Se guardará la tabla y se actualizará la tabla Auxiliar.
- Se conectará a un Looker Studio.
Los resultados
Ventajas
- Clasifica conceptos:
- Permite errores de escritura en keywords.
- Permite otros idiomas en las keywords.
- Permite emoticonos.
- Clasifica pocas keywords en otros.
- No se fija el número de grupos.
- Saca menos grupos que con K-Means.
- Los grupos son palabras, no raíces.
Inconvenientes
- Es lento, especialmente a la hora de clasificar.
- Es costoso (especialmente GPT 4). Aunque este punto depende del número de keywords.
Un ejemplo de dicho esquema funcional lo podemos encontrar aquí. Este es un archivo de Google Colab, hecho en Python, que demuestra lo mencionado a lo largo de esta guía y lo hemos clasificado en diferentes bloques para facilitar la comprensión.
Para hacer pruebas con este archivo, recomendamos hacer una copia, rellenar las credenciales de OpenAI y sustituir _MARCA_ que aparece a lo largo de este archivo por la marca a aplicar. También sería posible eliminar completamente este valor, para que los resultados fueran más genéricos.





