

Imagina que tienes delante una enorme caja de piezas de Lego…
diferentes formas, tamaños y colores, todo mezclado.
¿Cómo empezarías a ordenarla para entender qué tienes realmente? Probablemente harías montoncitos, ¿verdad? Un montón para los ladrillos rojos grandes, otro para las ruedas pequeñas, otro para las figuras… Intuitivamente, estarías agrupando las piezas similares.

Pues bien, en el mundo de los datos de marketing y analítica web, a menudo nos encontramos con una «caja de Lego-datos» similar: cientos de landing pages, miles de keywords, millones de interacciones de usuario… Datos valiosísimos, pero difíciles de abarcar si los miramos uno a uno. ¿No sería genial tener una forma automática de crear esos «montoncitos» para descubrir grupos de páginas con rendimiento parecido, segmentos de usuarios con comportamientos similares o keywords que funcionan de forma anómala?
Una opción para poder crear estos grupos es crear agrupaciones manuales definiendo nosotros las reglas por las que metemos un dato un grupo u otro: Así puedes definir regex manuales para clasificar URLs, o crear un histograma separando métricas de 100 en 100. Pero esto implica un conocimiento y simplicidad de los datos que no siempre vamos a tener. Otras veces, sencillamente, queremos pocos grupos y no tenemos ni idea de cuales son los criterios por los que un registro entraría en un grupo o en otro.
Aquí es donde entra en juego K-Means, una técnica de clusterización potentísima. Y lo mejor de todo es que, gracias a BigQuery ML, puedes aplicarla directamente sobre tus datos usando consultas SQL, sin necesidad de ser un experto en data science ni de salir de tu entorno de BigQuery.
Por ejemplo, nosotros podemos usar K-Means para extraer insights clave de los datos de GA4, Google Search Console, Crawlers y Bases de datos de nuestros clientes. Con esta técnica tenemos el potencial para:
- Segmentar automáticamente páginas o productos por su rendimiento (tráfico, conversión, ingresos…).
- Detectar usuarios con patrones de compra o navegación específicos.
- Identificar keywords o campañas con resultados fuera de lo común (¡para bien o para mal!).
- Agrupar contenido por similitud semántica (aunque esto lo veremos mejor en futuros posts sobre embeddings).
- Crear nuevas dimensiones o variables que enriquezcan nuestros análisis.
–
En este post, te vamos a guiar paso a paso para que entiendas qué es K-Means, cómo funciona en BigQuery ML y cómo puedes empezar a usarlo hoy mismo para poner orden en tus datos y tomar decisiones más inteligentes.
¡Vamos a ello!
¿Qué es eso del K-Means y la autoclusterización? (Desmitificando conceptos)
Empecemos por lo básico. La clusterización es simplemente el proceso de agrupar un conjunto de objetos (en nuestro caso, filas de datos: páginas, usuarios, keywords…) de tal manera que los objetos dentro del mismo grupo (llamado cluster) sean más similares entre sí que con los de otros grupos. Es como hacer los montoncitos de Lego que decíamos.
K-Means es uno de los algoritmos más populares para hacer esto. Su idea principal es bastante intuitiva y parte de darle nuestros datos y el número de grupos en el que queremos ordenarlos. Su proceso es tan simple (comparado con otros procesos ML) que podemos listar todos los pasos que da un entrenamiento de clusters K-Means muy fácilmente.
- Decide cuántos clusters (‘K’) quieres que se creen (total grupos).
- El algoritmo elige ‘K’ puntos iniciales al azar (o de forma un poco más inteligente) que actúan como los centros iniciales de los clusters. Estos centros se llaman centroides (quédate con esta palabra que es la más importante de los K-means). Piensa en ellos como el «corazón» o el punto más representativo de cada grupo.
- El sistema asigna cada uno de tus puntos de datos (cada página, cada usuario…) al centroide que tenga más cerca, basándose en las métricas que le hayas indicado (luego veremos cuáles).
- K-means, una vez lo tiene todo calculado, recalcula la posición de cada centroide, moviéndolo al punto medio de todos los puntos que se le han asignado. De esta forma esta nueva ubicación es más representativa de la realidad.
- Repite los pasos 3 y 4 varias veces: reasigna los puntos a los nuevos centroides y vuelve a calcular la posición de estos. El algoritmo realiza este proceso en bucle hasta que los centroides ya casi no se muevan al recalcularse. Cuando sus valores son muy semejantes entiende que que los grupos ya son estables y los deja así.
–
Así que este sistema lo único que hace al crear el modelo es definir los valores de las métricas medias de cada centroide. Estos centroides serán el corazón de cada cluster. De tus datos se calculará para cada uno (para cada fila de datos de tu tablas) la distancia con todos los centroides, así que el que quede más cerca es al que pertenece el grupo.
Al final, lo que obtienes es una etiqueta para cada uno de tus datos indicando a qué cluster pertenece el dato (el centroide más cercano).
¡Magia! Has creado grupos homogéneos automáticamente.
¿Y para qué sirve todo esto en nuestro día a día de marketing y análisis? Pues para un montón de cosas. Antes te he dicho ya algunas, pero vamos a seguir…
- Crear Audiencias de usuarios con comportamiento similar: Agrupandolas por sus datos de uso, revisita, objetivos cumplidos, etc.
- Identificar páginas de alto/bajo rendimiento: cogiendo las métricas de rendimiento en la disciplina que las estés investigando (en SEO podrías ver impresiones, clicks y conversiones)
- Agrupar productos por patrones de interés y compra,
- Detectar anomalías en cualquier sistema de métricas que midas…
–
En definitiva, los clusters de K-means se usan para simplificar la complejidad de los grandes volúmenes de datos (GA, GSC, Compras, stocks, cualquierBBDD grande) y encontrar patrones ocultos que nos ayuden a entender mejor qué está pasando.
El Primer Reto: ¿Cuántos Grupos (Clusters) Crear? (Decidiendo la ‘K’)
Aquí viene una de las partes cruciales (y a veces un poco subjetivas) de K-Means: elegir el número de clusters, la famosa ‘K’. El algoritmo necesita que le digas cuántos grupos quieres formar. Pero, ¿cuál es el número correcto? ¿Dos? ¿Cinco? ¿Veinte?
Elegir una ‘K’ adecuada es fundamental, porque afecta directamente a la calidad y utilidad de tus resultados:
- Si eliges una ‘K’ demasiado baja: Te arriesgas a crear clusters muy grandes y heterogéneos. Es como si en la caja de Lego solo hicieras dos montones: «piezas rojas» y «piezas no rojas». Dentro de «piezas no rojas» tendrías de todo (azules, amarillas, ruedas, figuras…), y ese grupo no te daría mucha información útil. En tus datos, podrías estar mezclando páginas de rendimiento muy diferente en el mismo cluster.
–
- Si eliges una ‘K’ demasiado baja: Te arriesgas a crear clusters muy grandes y heterogéneos. Es como si en la caja de Lego solo hicieras dos montones: «piezas rojas» y «piezas no rojas». Dentro de «piezas no rojas» tendrías de todo (azules, amarillas, ruedas, figuras…), y ese grupo no te daría mucha información útil. En tus datos, podrías estar mezclando páginas de rendimiento muy diferente en el mismo cluster.
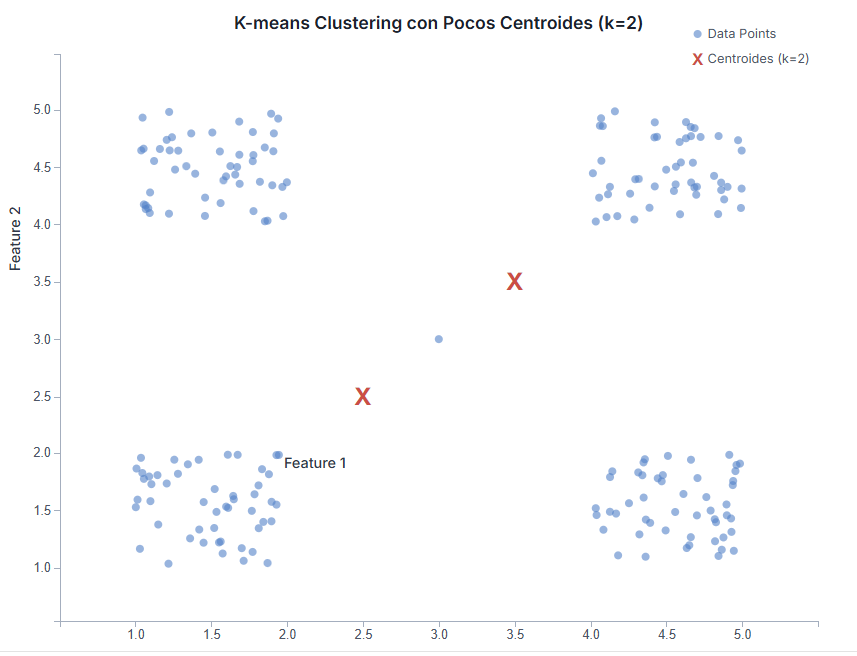
- Si eliges una ‘K’ demasiado alta: Puedes acabar con clusters muy pequeños, a veces con solo uno o dos elementos. Sería como hacer un montón para cada variación mínima de color de Lego («rojo claro», «rojo oscuro», «rojo anaranjado»…). Estos grupos tan específicos pueden ser difíciles de interpretar y generalizar. Además, corres el riesgo de «sobreajustar» (overfitting), creando grupos que reflejan el ruido o las particularidades de tus datos actuales, pero que no son representativos de patrones reales y estables.
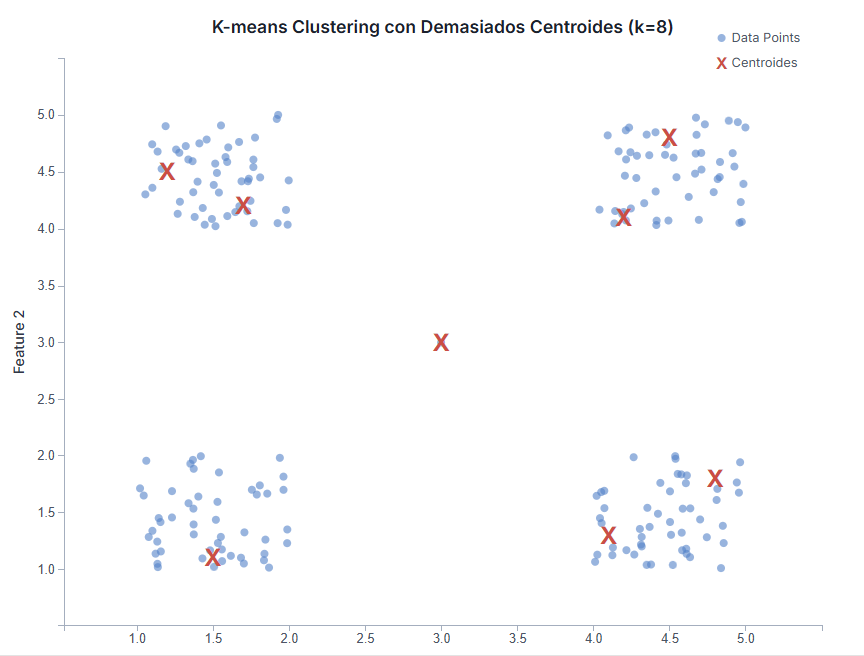
Entonces, ¿Cómo decidimos la ‘K’?
Hay varias aproximaciones:
- Conocimiento del Negocio:
A menudo, tú ya tienes una idea de cuántos segmentos naturales podrían existir. Si sabes que tienes tres tipos principales de clientes (ej: nuevos, recurrentes, VIPs), empezar probando con K=3 es un buen punto de partida. Si analizas páginas, podrías pensar en categorías como «informativas», «transaccionales», «blog», etc., y usar ese número como guía inicial.
– - Método del Codo (Elbow Method):
Esta es una técnica más basada en datos. Consiste en ejecutar K-Means varias veces, cada una con un número diferente de clusters (K=2, K=3, K=4, etc.). Para cada ejecución, se calcula una métrica que mide cuán compactos son los clusters (normalmente la «suma de cuadrados intra-cluster» o WCSS). Se dibuja una gráfica con la ‘K’ en el eje X y la WCSS en el eje Y. A medida que aumentas ‘K’, la WCSS generalmente disminuye (los grupos son más pequeños y compactos). Lo que buscamos es el punto en la gráfica donde la curva empieza a aplanarse, formando un «codo». Ese punto se considera a menudo un buen equilibrio entre tener suficientes clusters para capturar la estructura de los datos y no tener demasiados.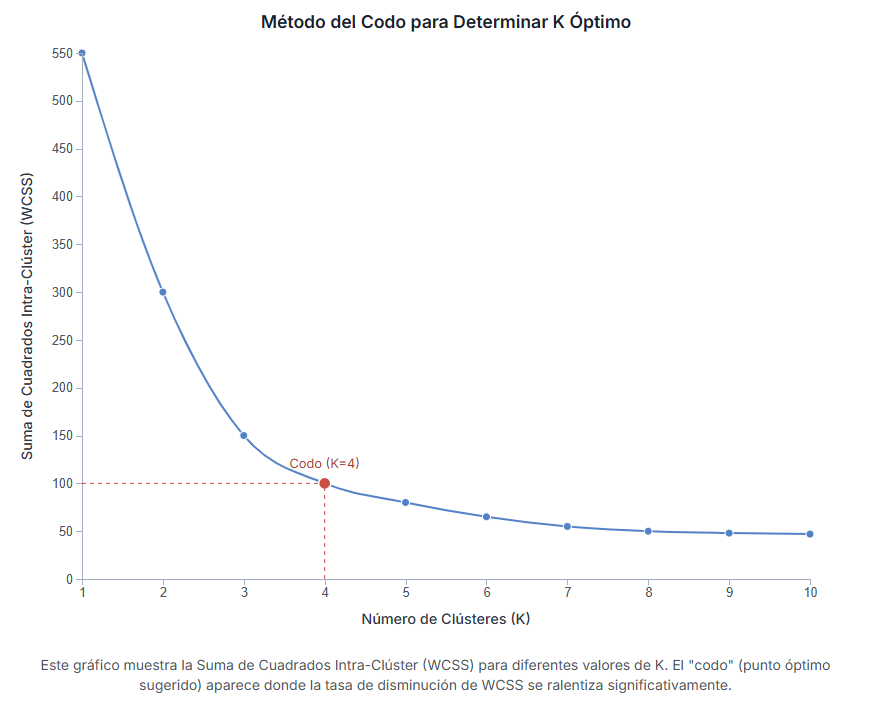
- Otras Métricas (Silhoutte Score, etc.):
Existen otras métricas estadísticas más avanzadas para evaluar la calidad de la clusterización con diferentes ‘K’. BigQuery ML no las calcula directamente al crear el modelo K-Means estándar, pero podrías calcularlas tú mismo a posteriori si necesitas más rigor.
– - Prueba y Error (Iteración):
No tengas miedo de probar varias ‘K’, examinar los clusters resultantes (¿tienen sentido? ¿son interpretables? ¿son útiles?) y ajustar la ‘K’ según lo que observes. Sí, entrenar varios modelos de k-means cada vez es un poco tedioso, pero si los vas entrenando en paralelo (por ejemplo, de golpe entrenas 5 modelos para 3, 4, 5, 6 y 7 clusters, luego solo te quedará ver cual ha ido mejor.
–
Lo importante es recordar que no siempre hay una única ‘K’ perfecta. A veces, diferentes ‘K’ pueden revelar distintos niveles de granularidad en tus datos, y ambos pueden ser útiles.
Manos a la obra: K-Means con SQL en BigQuery ML
Vale, ya entendemos la idea de qué es K-means y qué buscamos crear. ¿no? Ahora veamos lo mejor: hacerlo es sorprendentemente fácil en BigQuery. No necesitas instalar librerías de Python ni montar infraestructuras complejas. Todo se hace con un par de comandos SQL. Para los que usamos BigQuery para casi todos nuestros datos esto es una gozada.
Paso 1: Crear el modelo K-Means (`CREATE MODEL`)
Lo primero es «entrenar» o crear el modelo K-Means. Le decimos a BigQuery qué datos usar, cuántos clusters queremos (nuestra ‘K’) y algunas opciones más. Esto generará los centroides en el modelo de forma que luego lo podremos invocar para cualquier dato (que ya tengamos o futuro) y que nos diga al que cluster pertence y a qué distancia está de todos los centroides.
La sintaxis básica es así:
CREATE OR REPLACE MODEL `tu_proyecto.tu_dataset.nombre_del_modelo_kmeans`
OPTIONS(
model_type='KMEANS',
num_clusters=5, -- ¡Aquí pones la 'K' que has decidido!
kmeans_init_method='KMEANS++', -- Método para elegir los centroides iniciales (KMEANS++ suele ser el que mejor va y no hace falta cambiarlo)
standardize_features=TRUE -- ¡Muy importante! Normaliza las métricas para que todas pesen parecido sin importar su rango de volúmen.
) AS
SELECT
-- Aquí seleccionas SOLO las columnas NUMÉRICAS que quieres usar para agrupar
-- Ejemplo: clics, sesiones, tasa_conversion, ingresos_por_usuario...
metrica_numerica_1,
metrica_numerica_2,
otra_metrica_numerica
FROM
`tu_proyecto.tu_dataset.tabla_con_tus_datos`; -- La tabla donde están tus datos a clusterizar
Analicemos las `OPTIONS` que hemos usado para comprenderlas:
model_type='KMEANS':
Le dice a BigQuery que queremos un modelo K-Means.
–num_clusters=5:
Aquí especificas la ‘K’. Es el número de grupos que intentará encontrar.
–kmeans_init_method='KMEANS++':
Es la forma en que el algoritmo elige los puntos de partida para los centroides. ‘KMEANS++’ es generalmente mejor que un inicio totalmente aleatorio (‘RANDOM’). Déjalo en KMEANS++ y no le des más vueltas.
–standardize_features=TRUE:
¡Este es clave! Imagina que usas «sesiones» (que pueden ser miles) y «tasa de conversión» (que suele ser un número pequeño, como 0.02). Sin estandarizar, las sesiones dominarían totalmente el cálculo de distancias y la tasa de conversión apenas influiría. Poner esto a `TRUE` hace que BigQuery escale internamente todas las métricas para que tengan una importancia similar en la clusterización. Casi siempre querrás usarlo. Solo en un caso en el que tu estandarices las métricas para hacer unas más importantes que otras podrías no querer activarlo.
–
Y en el `SELECT`…
¡ojo! Aquí solo debes incluir las columnas numéricas que quieres que el algoritmo use para medir la similitud entre tus elementos. No incluyas IDs, nombres, URLs o fechas directamente aquí (luego veremos cómo conservarlos en tus consultas).
¿No tienes una tabla con los datos directamente preparados para ofrecer los números con los que crear los clusters?
No importa. Como puedes ver en la consulta la parte del SELECT es realmente un SELECT por lo que puedes calcular o recalcular los datos sin problema. Eso sí, si lo haces así ten en cuenta que cada vez que quieras calcular al cluster que pertenece un dato deberás repetir esta SELECT exactamente igual.
Paso 2: Aplicar el modelo para clasificar los datos (`ML.PREDICT`)
Una vez que la query anterior ha terminado (puede tardar un poco si tienes muchos datos), ya tienes tu modelo K-Means creado.
Ahora puedes usarlo para asignar cada una de tus filas de datos a uno de los clusters. Esto se hace con la función `ML.PREDICT`:
SELECT
* -- Esto te devolverá tus columnas originales MÁS las columnas generadas por ML.PREDICT, si necesitas menos datos, defínelos aquí.
FROM
ML.PREDICT(MODEL `tu_proyecto.tu_dataset.nombre_del_modelo_kmeans`,
(
SELECT
-- Aquí debes incluir las MISMAS columnas NUMÉRICAS que usaste en el CREATE MODEL
metrica_numerica_1,
metrica_numerica_2,
otra_metrica_numerica,
-- Y TAMBIÉN puedes incluir aquí los IDs o dimensiones que quieras conservar para identificar cada fila
id_elemento,
nombre_elemento,
url_pagina -- etc.
FROM
`tu_proyecto.tu_dataset.tabla_con_tus_datos`
)
);
Esta query toma tu modelo recién creado y la tabla de datos (es importante que tenga las mismas métricas numéricas que usaste para entrenar) y añade nuevas columnas al resultado. Sí la función lo unico que hace es respetar tu SELECT y añadirle las columnas de clusterización.
Las columnas más importantes que genera `ML.PREDICT` para K-Means son:
NEAREST_CENTROID_ID:
Un número (empezando por 1) que indica el ID del cluster al que ha sido asignado cada elemento (fila). ¡Esta es la etiqueta de grupo que buscábamos!
–CENTROID_DISTANCES:
Un array (una lista) de números. Contiene la distancia euclidiana desde el elemento hasta el centroide de cada uno de los ‘K’ clusters. El primer número es la distancia al centroide 1, el segundo al centroide 2, y así sucesivamente.
–
Ahora veamos cómo trabajar con esta salida de datos.
¿Quieres lanzar una demo de K-Means en tu BigQuery sin pensártelo mucho?
Por mucho que intente explicarlo todo en este post paso a paso, lo cierto es que hasta que no hagas tus propias pruebas en BigQuery no terminarás de asimilarlo. Por eso te voy a dejar dos queries sencillas. Con ellas podrás crear con un sencillo corta y pega un modelo K-means y ver los resultados en los que clasifica unos datos ficticios. Por supuesto, por simplificar, estas queries van a ser con muy pocos datos y totalmente inútiles, pero te pondrán sobre la marcha.
Paso 1: Query para crear un modelo K-means ficticio en tu dataset
Copia y pega esta query en tu BigQuery despues de reemplazar dataset y proyecto.
-- IMPORTANTE: Reemplaza `tu_proyecto` y `tu_dataset` con los tuyos. (y sí, eso significa que debes tener ya un proyecto y dataset con facturación activada)
CREATE OR REPLACE MODEL `tu_proyecto.tu_dataset.kmeans_demo_model_sin_tabla`
OPTIONS(
model_type='KMEANS',
num_clusters=2, -- Vamos a buscar 2 clusters en estos datos de ejemplo
standardize_features=TRUE
) AS
WITH DatosFicticios AS (
-- Generamos algunos datos de ejemplo directamente aquí
SELECT 'Punto_A' AS id, 1.0 AS metrica1, 2.0 AS metrica2 UNION ALL
SELECT 'Punto_B' AS id, 1.5 AS metrica1, 1.8 AS metrica2 UNION ALL
SELECT 'Punto_C' AS id, 1.2 AS metrica1, 1.5 AS metrica2 UNION ALL -- Grupo 1 (valores bajos)
SELECT 'Punto_D' AS id, 8.0 AS metrica1, 9.0 AS metrica2 UNION ALL
SELECT 'Punto_E' AS id, 8.5 AS metrica1, 8.8 AS metrica2 UNION ALL
SELECT 'Punto_F' AS id, 8.2 AS metrica1, 9.5 AS metrica2 -- Grupo 2 (valores altos)
)
-- El modelo se entrena solo con las métricas numéricas
SELECT
metrica1,
metrica2
FROM DatosFicticios;
Cuando lances la query tendrás que esperar unos cuantos segundos. Incluso con esta muestra tan pequeña necesita ir colocando los centroides en su sitio poco a poco. Cuando acabes puedes ver detalles de la ejecución para crear el modelo.

A partir de ese momento verás en tu explorador de BigQuery como aparece la carpeta «Modelos» y dentro de esta el modelo que acabas de crear:

Eso significa que ya puedes usar tu modelo en cualquier query y empezar a ver en qué cluster acaba cada fila de datos.
Paso 2: Query para usar el modelo y ver sus datos.
Ahora vuelve a abrir el editor de queries de BigQuery y lanza esta query con ML.PREDICT para aplicar el modelo ya entrenado.
-- IMPORTANTE: Asegúrate de que `tu_proyecto` y `tu_dataset` son los mismos que en el Paso 1.
WITH DatosFicticios AS (
-- ¡Exactamente los mismos datos generados que en el Paso 1!
SELECT 'Punto_A' AS id, 1.0 AS metrica1, 2.0 AS metrica2 UNION ALL
SELECT 'Punto_B' AS id, 1.5 AS metrica1, 1.8 AS metrica2 UNION ALL
SELECT 'Punto_C' AS id, 1.2 AS metrica1, 1.5 AS metrica2 UNION ALL -- Grupo 1
SELECT 'Punto_D' AS id, 8.0 AS metrica1, 9.0 AS metrica2 UNION ALL
SELECT 'Punto_E' AS id, 8.5 AS metrica1, 8.8 AS metrica2 UNION ALL
SELECT 'Punto_F' AS id, 8.2 AS metrica1, 9.5 AS metrica2 -- Grupo 2
)
-- Usamos ML.PREDICT sobre el modelo creado en el Paso 1
SELECT
* -- Mostramos todas las columnas originales + las de predicción
FROM
ML.PREDICT(MODEL `tu_proyecto.tu_dataset.kmeans_demo_model_sin_tabla`,
(
-- Le pasamos a PREDICT tanto el ID como las métricas numéricas
SELECT id, metrica1, metrica2 FROM DatosFicticios
)
);
Cuando la lances te encontrarás con un resultado como este:

Esto es que todo ha ido bien.
- CENTROID_ID: El Cluster donde se ha asociado este dato.
- Resto de datos: El array de NEAREST_CENTROID_DISTANCE con la distancia de esos datos a todos los demás.
–
Juega con las queries y familirizate con este tipo de entrenamientos y resultados. Pronto empezarás a tener ideas de qué podrías hacer con tus propios conjuntos de datos.
¿Todo visto? Vamos ahora a interpretar y simplificar los resultados de K-Means
La salida de `ML.PREDICT` es completa, pero a veces queremos algo más directo.
Lo más común: Saber solo a qué grupo pertenece cada dato
En la mayoría de los casos, lo que más nos interesa es simplemente saber a qué cluster (grupo) pertenece cada uno de nuestros elementos (páginas, usuarios, keywords…). Queremos esa etiqueta `NEAREST_CENTROID_ID` para poder analizar luego el rendimiento por grupo, segmentar campañas, etc.
Podemos simplificar la query anterior para obtener una tabla más limpia, que contenga nuestros datos originales más una columna con el ID del cluster asignado:
-- Guardamos el resultado en una nueva tabla para facilitar el análisis posterior
CREATE OR REPLACE TABLE `tu_proyecto.tu_dataset.tabla_con_clusters_asignados` AS
SELECT
datos_originales.*, -- Selecciona todas las columnas originales que te interesen
prediccion.NEAREST_CENTROID_ID AS cluster_id -- Añade solo el ID del cluster asignado, renombrado para claridad
FROM
ML.PREDICT(MODEL `tu_proyecto.tu_dataset.nombre_del_modelo_kmeans`,
(
SELECT
* -- Asegúrate de que esta subconsulta incluye un ID único y las métricas numéricas usadas en el modelo
FROM
`tu_proyecto.tu_dataset.tabla_con_tus_datos`
)
) AS prediccion
-- Unimos la predicción con los datos originales usando algún ID único si es necesario para recuperar todas las columnas
-- (A veces ML.PREDICT no devuelve todas las columnas originales si hay tipos complejos, JOIN es más seguro)
JOIN
`tu_proyecto.tu_dataset.tabla_con_tus_datos` AS datos_originales
ON -- Asegúrate de que tienes un campo ID único en tu tabla original
prediccion.id_elemento = datos_originales.id_elemento; -- Cambia 'id_elemento' por tu campo identificador real
El resultado de esta query sería una tabla como esta (ejemplo ficticio para páginas web):
| url_pagina | sesiones | tasa_conversion | cluster_id |
|---|---|---|---|
| /pagina-a | 1500 | 0.03 | 2 |
| /pagina-b | 250 | 0.08 | 4 |
| /blog/articulo-nuevo | 5000 | 0.01 | 1 |
| /producto/widget-premium | 800 | 0.05 | 2 |
| /contacto | 150 | 0.15 | 4 |
| /pagina-c | 4500 | 0.01 | 1 |
| … | … | … | … |
Esto es mucho más manejable y además te va a ahorrar costes, pues a partir de ahora puedes consultar solo a los datos de esa tabla ya calculada sin tener que invocar al modelo cada vez. Ahora puedes hacer un `GROUP BY cluster_id` para ver las métricas medias de cada grupo, filtrar por cluster, etc.
¿Cuándo usar esto? Casi siempre. Para segmentar, etiquetar, crear nuevas dimensiones en tus dashboards, analizar rendimiento agregado por grupo…
¿Los clusters tienen que ser siempre números consecutivos? ¿no tienen un nombre descriptivo?
No solo no tienen nombre sino que el número (1, 2, 3) en si no significa nada. Son solo agrupaciones. Lo suyo es que una vez las tengas las describas para poder entenderlas mejor. ¿Cómo? Lanzando una consulta que describa los datos medios de cada grupo. Esta consulta usará un GROUP BY por cluster id y sacará las Medias de cada métrica clusterizada en cada cluster. Así tendrás un valor más descriptivo.
Podemos lanzar una query sobre la tabla ya generada en el paso anterior como esta:
-- Analizando los clusters: Calcular métricas promedio por cada cluster de landings
SELECT
cluster_id,
COUNT(*) AS numero_landings, -- ¿Cuántas landings hay en cada cluster?
-- Promedios de las métricas usadas para clusterizar (y otras relevantes)
AVG(gsc_clicks) AS media_gsc_clicks,
AVG(gsc_impressions) AS media_gsc_impressions,
AVG(gsc_ctr) AS media_gsc_ctr,
AVG(gsc_avg_pos) AS media_gsc_posicion, -- Promedio de la posición media de GSC
AVG(ga4_sessions) AS media_ga4_sessions,
AVG(ga4_conv_rate) AS media_ga4_tasa_conversion,
AVG(ga4_avg_duration) AS media_ga4_duracion
FROM
`tu_proyecto.tu_dataset.landings_con_cluster_k5` -- Usamos la tabla que acabamos de crear
GROUP BY
cluster_id
ORDER BY
cluster_id; -- Ordenamos para ver los clusters en orden
Esto nos definiría el valor medio de las métricas que hay en cada cluster. Es decir, nos creará una tabla como la que sigue:
| cluster _id | total_ landings | gsc_ clicks | gsc_ impressions | gsc_ ctr | gsc_ posicion | ga4_ sessions | ga4_ tasa_ conversion | ga4_ duracion |
|---|---|---|---|---|---|---|---|---|
| 1 | 55 | 150.5 | 8000.2 | 0.02 | 18.5 | 300.1 | 0.12 | 150.6 |
| 2 | 120 | 450.8 | 60000.5 | 0.01 | 22.1 | 1100.3 | 0.008 | 45.1 |
| 3 | 15 | 4800.2 | 120000.1 | 0.04 | 3.1 | 9500.8 | 0.09 | 190.3 |
| 4 | 30 | 70.1 | 1500.9 | 0.05 | 6.5 | 150.4 | 0.18 | 260.8 |
| 5 | 85 | 9500.6 | 450000.3 | 0.02 | 9.2 | 18000.5 | 0.02 | 70.2 |
¡Ahora sí podemos ponerle nombre a los clusters!
Vamos uno a uno intentando entender el tipo de datos que contiene cada uno y sacamos nuestra parte creativa (o tiramos de IA generativa, claro)
- Cluster 1: «Joyas Ocultas / Potencial SEO«.
Pocas landings, bajo tráfico GSC, posición media mala, pero ¡muy buena tasa de conversión y duración!
– - Cluster 2: «Problemas / Necesitan Optimización Urgente«.
Muchas landings, tráfico GSC medio-bajo, mala posición, sesiones GA4 decentes pero conversión y duración bajas
– - Cluster 3: «Estrellas«.
Pocas landings pero son las ‘Top’. Mucho tráfico GSC, muy buena posición, muchas sesiones GA4, buena conversión y duración
– - Cluster 4: «Nicho Muy Específico / Alto Valor«.
Pocas landings, muy poco tráfico GSC pero excelente CTR y posición, sesiones GA4 bajas pero ¡la mejor tasa de conversión y duración!
– - Cluster 5: «Contenido Muy Visto / Baja Conversión«
Bastantes landings, muchísimo tráfico GSC y sesiones GA4, pero CTR bajo, conversión baja y poca duración
–
Este análisis de promedios es fundamental para interpretar los resultados de K-Means y decidir las acciones a tomar para cada segmento descubierto.
¿Y las distancias a los centroides? ¿Para qué Sirven?
Aunque normalmente nos quedamos con el `NEAREST_CENTROID_ID`, la columna `CENTROID_DISTANCES` que también devuelve `ML.PREDICT` tiene su utilidad en casos más específicos (es el nivel 2 del uso de K-means):
- Detectar Outliers (Anomalías):
Un elemento que está muy, muy lejos de su propio centroide (y probablemente de todos los demás) podría ser un caso atípico. Imagina una keyword con millones de impresiones pero cero clics. K-Means podría asignarla a un cluster, pero su distancia a ese centroide sería enorme. Examinando los elementos con las mayores distancias a su centroide asignado podemos encontrar estos outliers.
– - Evaluar la «claridad» de la asignación:
Si un elemento está casi a la misma distancia de dos centroides diferentes, significa que está «a medio camino» entre dos grupos. Esto puede indicar que el elemento no pertenece claramente a ninguno, o que quizás la ‘K’ elegida no separa bien esos casos.
– - Análisis más finos:
En algunos escenarios avanzados, podrías querer usar estas distancias para análisis posteriores, como ponderar elementos según su cercanía al centroide.
–
La salida completa de `ML.PREDICT` se vería así (ejemplo ficticio, K=4):
| url_pagina | sesiones | tasa_ conversion | NEAREST_ CENTROID _ID | CENTROID_DISTANCES |
|---|---|---|---|---|
| /pagina-a | 1500 | 0.03 | 2 | [34.5, 12.1, 150.8, 95.2] |
| /pagina-b | 250 | 0.08 | 4 | [210.3, 80.5, 400.1, 8.7] |
| /blog/articulo-nuevo | 5000 | 0.01 | 1 | [5.2, 250.6, 600.0, 550.9] |
| /producto/widget-prem | 800 | 0.05 | 2 | [98.1, 15.3, 220.4, 60.8] |
| /contacto | 150 | 0.15 | 4 | [300.7, 150.2, 550.9, 5.1] |
| /outlier-raro | 5 | 0.01 | 3 | [800.1, 750.6, 680.3, 790.4] |
| … | … | … | … | … |
Fíjate por ejemplo en `/outlier-raro`: aunque se asigna al cluster 3, su distancia a *todos* los centroides es muy alta. Esto nos haría sospechar. Y fíjate en `/pagina-a`: su distancia al centroide 2 (12.1) es la menor, por eso se le asigna ese ID, pero la distancia al centroide 1 (34.5) tampoco es gigantesca.
Aplicaciones Prácticas de K-Means en Marketing Digital y Analítica
Ahora que sabemos cómo funciona, veamos cómo aplicar K-Means a los datos que manejamos habitualmente en IKAUE, como los de Google Analytics 4, Google Search Console o datos de producto.
Autoclusterización para crear dimensiones macro:
Segmentando Landing Pages (SEO/GA4)
El reto: Tienes cientos o miles de landing pages. ¿Cómo agruparlas por rendimiento para saber dónde enfocar tus esfuerzos de optimización (SEO, CRO)?
Datos a usar: Métricas combinadas de GSC (clics, impresiones, CTR, posición media) y GA4 (sesiones, tasa de conversión por sesión, ingresos por sesión, duración media de sesión) a nivel de landing page. ¡Asegúrate de que sean todas numéricas!
Ejemplo de uso: Crear clusters como «Alto tráfico, baja conversión», «Joyas ocultas (baja visibilidad, alta conversión)», «Estrellas (alto tráfico, alta conversión)», «Páginas problemáticas», etc.
Query de creación de modelo (ejemplo ficticio, K=5):
-- Crear modelo para clusterizar landings por rendimiento SEO y Web
CREATE OR REPLACE MODEL `tu_proyecto.tu_dataset.kmeans_landings_rendimiento_k5`
OPTIONS(model_type='KMEANS', num_clusters=5, standardize_features=TRUE) AS
SELECT
-- Métricas de GSC (asegúrate de tratar valores nulos o infinitos si los hay)
COALESCE(gsc.clicks, 0) AS gsc_clicks,
COALESCE(gsc.impressions, 0) AS gsc_impressions,
COALESCE(gsc.ctr, 0) AS gsc_ctr,
-- Invertir posición media para que más alto sea 'mejor' (más cerca de 1)
-- Evitar división por cero si la posición es 0
SAFE_DIVIDE(1, COALESCE(gsc.average_position, 1000)) AS gsc_inv_avg_position,
-- Métricas de GA4
COALESCE(ga4.sessions, 0) AS ga4_sessions,
COALESCE(ga4.session_conversion_rate, 0) AS ga4_conv_rate,
COALESCE(ga4.average_session_duration, 0) AS ga4_avg_duration
FROM
`tu_proyecto.tu_dataset.datos_gsc_agrupados_por_pagina` AS gsc
-- Usamos LEFT JOIN por si hay páginas en GA4 que no están en GSC (o viceversa)
FULL OUTER JOIN
`tu_proyecto.tu_dataset.datos_ga4_agrupados_por_landing` AS ga4
ON gsc.page = ga4.landing_page
-- Filtramos páginas con muy pocas impresiones/sesiones para no distorsionar
WHERE COALESCE(gsc.impressions, 0) > 50 AND COALESCE(ga4.sessions, 0) > 10;
Query de predicción y asignación (ejemplo ficticio):
-- Asignar cada landing page a un cluster de rendimiento
CREATE OR REPLACE TABLE `tu_proyecto.tu_dataset.landings_con_cluster_k5` AS
WITH DatosParaPredecir AS (
-- Repetimos la misma lógica de selección y limpieza que en CREATE MODEL
SELECT
COALESCE(gsc.page, ga4.landing_page) AS landing_page, -- Clave única
COALESCE(gsc.clicks, 0) AS gsc_clicks,
COALESCE(gsc.impressions, 0) AS gsc_impressions,
COALESCE(gsc.ctr, 0) AS gsc_ctr,
SAFE_DIVIDE(1, COALESCE(gsc.average_position, 1000)) AS gsc_inv_avg_position,
COALESCE(ga4.sessions, 0) AS ga4_sessions,
COALESCE(ga4.session_conversion_rate, 0) AS ga4_conv_rate,
COALESCE(ga4.average_session_duration, 0) AS ga4_avg_duration
FROM
`tu_proyecto.tu_dataset.datos_gsc_agrupados_por_pagina` AS gsc
FULL OUTER JOIN
`tu_proyecto.tu_dataset.datos_ga4_agrupados_por_landing` AS ga4
ON gsc.page = ga4.landing_page
WHERE COALESCE(gsc.impressions, 0) > 50 AND COALESCE(ga4.sessions, 0) > 10
)
SELECT
dp.landing_page,
pred.NEAREST_CENTROID_ID AS cluster_id,
-- Podemos traer de vuelta las métricas originales para analizar los clusters
dp.gsc_clicks, dp.gsc_impressions, dp.gsc_ctr, (1/dp.gsc_inv_avg_position) AS gsc_avg_pos,
dp.ga4_sessions, dp.ga4_conv_rate, dp.ga4_avg_duration
FROM
ML.PREDICT(MODEL `tu_proyecto.tu_dataset.kmeans_landings_rendimiento_k5`, TABLE DatosParaPredecir) AS pred
JOIN DatosParaPredecir AS dp ON pred.landing_page = dp.landing_page; -- Unir por la clave única
Resultado (tabla ficticia `landings_con_cluster_k5`):
| landing _page | cluster _id | gsc_ clicks | gsc_ impressions | gsc_ ctr | gsc_ avg_pos | ga4_ sessions | ga4_ conv_rate | ga4_ avg_duration |
|---|---|---|---|---|---|---|---|---|
| /pagina-estrella | 3 | 5000 | 100000 | 0.05 | 2.5 | 10000 | 0.08 | 180 |
| /pagina-potencial | 1 | 100 | 5000 | 0.02 | 15.0 | 200 | 0.10 | 120 |
| /blog/post-viral | 5 | 10000 | 500000 | 0.02 | 8.0 | 20000 | 0.01 | 60 |
| /pagina-problema | 2 | 500 | 50000 | 0.01 | 25.0 | 1000 | 0.005 | 30 |
| /producto-nicho | 4 | 50 | 1000 | 0.05 | 5.0 | 100 | 0.15 | 240 |
| … | … | … | … | … | … | … | … | … |
Beneficio: ¡Ahora puedes analizar cada cluster! El cluster 3 son tus estrellas, el 1 necesita más visibilidad SEO, el 5 mucho tráfico pero poca conversión (¿problemas de CRO o contenido informativo?), el 2 necesita una revisión profunda… Enfocas tus recursos donde más impacto tendrán.
Detección de Outliers: Keywords Anómalas (GSC)
El reto: Identificar keywords de Google Search Console con comportamiento extraño (muchas impresiones y CTR casi nulo, posición media altísima pero sin clics…).
Datos a usar: Clics, impresiones, CTR, posición media por `query` de GSC.
Ejemplo de uso: Usar K-Means para encontrar grupos «normales» y luego buscar las keywords que quedan muy lejos de cualquier centroide.
Query de predicción usando distancias (ejemplo ficticio sobre un modelo `kmeans_keywords_gsc_k4` ya creado):**
-- Encontrar keywords outliers basado en la distancia a su centroide más cercano
WITH PrediccionesConDistancia AS (
SELECT
query, -- El identificador de la keyword
NEAREST_CENTROID_ID,
-- Extraemos la distancia al centroide asignado del array CENTROID_DISTANCES
-- ¡OJO! Los IDs de centroide empiezan en 1, pero los índices de array en 0. Hay que restar 1.
CENTROID_DISTANCES[OFFSET(CAST(NEAREST_CENTROID_ID AS INT64) - 1)] AS distancia_al_centroide
FROM
ML.PREDICT(MODEL `tu_proyecto.tu_dataset.kmeans_keywords_gsc_k4`,
(
SELECT query, clicks, impressions, ctr, SAFE_DIVIDE(1, average_position) AS inv_avg_pos
FROM `tu_proyecto.tu_dataset.datos_gsc_por_keyword`
WHERE impressions > 20 -- Filtrar keywords con muy pocas impresiones
)
)
)
-- Calculamos un umbral (ej: percentil 98 de la distancia) para marcar outliers
, UmbralOutlier AS (
SELECT APPROX_QUANTILES(distancia_al_centroide, 100)[OFFSET(98)] AS umbral_distancia
FROM PrediccionesConDistancia
)
SELECT
p.query,
p.NEAREST_CENTROID_ID AS cluster_id,
p.distancia_al_centroide,
(p.distancia_al_centroide > (SELECT umbral_distancia FROM UmbralOutlier)) AS es_outlier_probable
FROM
PrediccionesConDistancia p
ORDER BY
distancia_al_centroide DESC; -- Ordenamos para ver las más lejanas primero
Resultado (tabla ficticia):
| query | cluster_id | distancia_al_centroide | es_outlier_probable |
|---|---|---|---|
| keyword muy rara sin clics | 2 | 150.75 | true |
| otra keyword extraña | 4 | 120.10 | true |
| keyword normal cluster 1 | 1 | 5.80 | false |
| keyword buena cluster 3 | 3 | 8.15 | false |
| … | … | … | … |
Beneficio: Investigar esas keywords marcadas como outliers. ¿Son irrelevantes? ¿Hay un problema técnico en la SERP? ¿Canibalización? Permite detectar problemas u oportunidades que pasarían desapercibidas.
Comprensión de Datos: Agrupando Comportamientos de Usuario (GA4)
El reto: ¿Podemos identificar grupos de usuarios con patrones de interacción similares en nuestra web o app, usando datos de GA4 exportados a BigQuery?
Datos a usar: Métricas agregadas por `user_pseudo_id` (o `user_id` si lo tienes configurado): número total de sesiones, duración media de sesión, total páginas vistas, número de eventos clave (ej: `purchase`, `add_to_cart`, `form_submit`), ingresos totales generados, días desde la última visita, etc.
Ejemplo de uso: Crear segmentos como «Usuarios fieles compradores», «Visitantes ocasionales de blog», «Usuarios perdidos», «Nuevos interesados», etc.
Query: La estructura sería muy similar a la del ejemplo de Landing Pages, pero seleccionando métricas a nivel de usuario desde la tabla de exportación de GA4 (agrupando por `user_pseudo_id`). No la repetimos aquí por brevedad.
Beneficio: Poder personalizar la experiencia en la web para cada cluster, dirigir campañas de remarketing o email más específicas, entender qué tipos de usuarios convierten mejor, etc.
Clusterización Semántica (¡Spoiler de futuros posts!)
El reto: Agrupar keywords, títulos de página o descripciones de producto no por sus métricas de rendimiento, sino por su significado. Por ejemplo, agrupar todas las keywords relacionadas con «zapatillas deportivas baratas» aunque tengan clics y CTRs diferentes.
¿Cómo? Aquí K-Means solo es el segundo paso. Primero, necesitamos convertir esos textos en representaciones numéricas que capturen su significado. Estos números se llaman embeddings vectoriales. Se generan usando otros modelos de ML/IA (como los modelos de lenguaje tipo Gemini que vimos en posts anteriores, o modelos específicos para embeddings). Una vez que tienes un vector numérico para cada texto, ¡entonces sí puedes aplicar K-Means a esos vectores!
Este tema es tan potente que le dedicaremos un post específico. Te enseñaremos cómo generar embeddings directamente en BigQuery ML y luego usar K-Means para crear clusters semánticos de tus contenidos o keywords. ¡Imagina poder analizar el rendimiento SEO por *temática* automáticamente!
Otros ejemplos rápidos:
- Clusterización de Productos (Datos Ecommerce/GA4):
Agrupar productos por patrones de venta (unidades vendidas, ingresos, margen, ratio visualización/compra, ratio añadido_carrito/compra). Útil para detectar qué productos se venden juntos, cuáles necesitan promoción, gestión de stock…
– - Agrupación de Campañas de Publicidad (Datos Ads):
Clusterizar campañas (Google Ads, Meta Ads…) por KPIs clave (ROAS, CPA, CTR, Tasa Conversión, Coste). Ayuda a identificar qué tipos de campañas funcionan mejor para diferentes objetivos y optimizar la asignación de presupuesto.
–
¿Qué datos sí y qué datos no usar con K-Means?
(Consejos Clave)
K-Means es potente, pero no funciona bien con cualquier tipo de dato. Es crucial entender qué darle de comer al algoritmo.
Lo Ideal: Datos Numéricos y Comparables
- Métricas completas:
Necesitamos que todos los datos que usamos dispongan de las métricas que vamos a incluir en el entrenamiento y en la predicción. Esto siginifica que filas de datos con huecos o nulls no nos servirán para trabajar.
– - Métricas Continuas o Discretas Significativas:
K-Means se basa en calcular distancias. Funciona mejor con números que representan cantidades o magnitudes: clics, sesiones, tiempo en página, ingresos, número de compras, edad, etc.
– - La Importancia de la Escala (¡Recuerda `standardize_features=TRUE`!):
Si metes métricas con rangos muy dispares (ej: Impresiones [millones] y CTR [decimales entre 0 y 1]), las de mayor magnitud dominarán por completo. Usar `standardize_features=TRUE` al crear el modelo es casi obligatorio para que todas las variables contribuyan de forma equitativa.
–
Los Retos: Cuidado con las Categorías y los Textos
- Datos Categóricos (Texto o Banderas):
K-Means no entiende directamente categorías como «País» (‘España’, ‘Francia’), «Dispositivo» (‘Móvil’, ‘Tablet’) o «Tipo de Cliente» (‘Nuevo’, ‘Recurrente’). Si quieres usar esta información para clusterizar, necesitas convertirla primero a formato numérico.
Técnicas como one-hot encoding (crear una columna binaria 0/1 para cada categoría) pueden servir, aunque BQML no lo hace automáticamente en K-Means (sí en otros tipos de modelos). Esto añade complejidad a la preparación de datos.
De todas formas lo que no es aconsejable es que hagas estas transformaciones sin seguir una escala. Por ejeplo si usas los ID de categoría de tu web (supongamos que tu web tiene 200 categorías con ID del 1 al 200) Kmeans entenderá que la categoría con ID 1 esta muy cerca de la de ID 2 y eso no tiene porque ser cierto. Si vas a trabajar con one-hot-encoding intentar ordenar los datos por semejanzas (por ejemplo, podrias ordenar los ID de país por volúmen de facturación o por coordenadas geográficas o por algún cálculo de grados de culturas)
– - Textos Libres:
Olvídate de meter directamente el texto de una descripción de producto, el contenido de un artículo o una query de búsqueda. K-Means no puede calcular distancias sobre texto crudo. Necesitas extraer características numéricas de ese texto (ej: longitud, número de palabras clave específicas) o, la solución más avanzada y potente, convertir el texto en embeddings (vectores numéricos) como mencionamos antes.
– - IDs y Fechas: No uses identificadores únicos (`user_id`, `product_sku`, `order_id`) como si fueran métricas para clusterizar. ¡No tienen significado numérico para agrupar! Tampoco uses fechas directamente; si quieres usar información temporal, calcula métricas numéricas a partir de ellas (ej: «días desde la última visita», «mes de la compra»).
– - Un Error Común: Intentar meter todo lo que tienes en la tabla dentro del `SELECT` del `CREATE MODEL`. ¡Recuerda! Solo las métricas numéricas que definen la similitud que buscas. Pero incluso aunque tengas muchas métricas numéricas es muy probable que muchas no tenga sentido tenerlas en cuenta para clusterizar.
–
El consejo de IKAUE: Antes de lanzar `CREATE MODEL`, piensa cuidadosamente: ¿Qué elementos quiero agrupar? ¿Y basándome en qué *características numéricas* medibles son similares o diferentes esos elementos? Si tienes dudas sobre cómo preparar tus datos categóricos o textuales, o sobre qué métricas elegir, ¡es un buen momento para preguntarnos!
Conclusión: Empieza a segmentar hoy mismo
¿Qué te lo impide?
¡Y eso es todo por ahora sobre K-Means en BigQuery ML! Como has visto, lo que antes parecía territorio exclusivo de data scientists con código complejo, ahora está al alcance de tu mano con unas pocas consultas SQL. La capacidad de encontrar grupos ocultos y segmentar automáticamente tus datos de marketing y analítica es una herramienta increíblemente valiosa.
No te agobies intentando hacer el análisis más sofisticado el primer día. Nuestro consejo es que empieces poco a poco:
- Elige un conjunto de datos relativamente simple y que conozcas bien. ¿Quizás tus 50 keywords principales de marca de GSC? ¿O tus 100 landing pages con más sesiones en GA4?
– - Selecciona solo 2 o 3 métricas numéricas clave para empezar (ej: clics e impresiones para keywords; sesiones y tasa de conversión para landings).
– - Prueba a crear un modelo con una ‘K’ pequeña (K=3 o K=4). Usa `standardize_features=TRUE`.
– - Lanza `ML.PREDICT` y examina los resultados. ¿A qué cluster va cada elemento? ¿Puedes calcular las métricas medias por cluster? ¿Tienen sentido esos grupos?
–
Familiarízate con el proceso, juega con diferentes ‘K’ y distintas métricas. Verás que pronto le coges el truco y la clusterización se convierte en una parte fundamental de tu caja de herramientas analíticas. Te ayudará a entender mejor a tus usuarios, a optimizar tu contenido y tus campañas, y en definitiva, a tomar decisiones más informadas.
Y por supuesto, si te encuentras con datos más complejos, necesitas ayuda para interpretar los resultados, o quieres llevar tus análisis de segmentación al siguiente nivel (quizás combinando K-Means con otras técnicas o con los famosos embeddings), recuerda que en IKAUE estamos para ayudarte. Tenemos mucha experiencia aplicando estas técnicas para sacar el máximo partido a los datos de nuestros clientes.





