

Uno de los puntos clave en todo lo que hacemos día a día dentro de la analítica digital en los fogones de IKAUE es la extracción, transformación y carga de datos (lo que en inglés se conoce como ETL, por Extract, Transform and Load). Ingentes cantidades de datos de diferentes fuentes que nos ayudan a construir toda clase de tableros de visualización con sus gráficos y que nos permiten descubrir nuevos focos de análisis o medir la repercusión de determinadas acciones a nivel de negocio.
Una de estas fuentes de datos es Search Console, la cual (tal como reza su página de producto) es un servicio gratuito (con un matiz) que proporciona información sobre la forma en que Google rastrea, indexa y publica nuestra web.
Esta información, además de mostrarse en una interfaz bastante clara y funcional, se puede extraer de dos formas diferentes: mediante una exportación automática que se puede configurar y que requiere (en este caso) un proyecto de Google Cloud (con unos costes relativos al almacenamiento de datos en BigQuery, siendo este el matiz al que me refería con anterioridad) y mediante la API que Google pone a nuestra disposición.
Y concretamente, tal y como hemos adelantado, este artículo lo dedicaremos a explicar cómo realizar esa extracción vía API usando Cloud Functions. Pero antes…
1. ¿Qué sabemos de Cloud Functions?
Recordemos: Cloud Functions es un entorno de ejecución de código de tipo serverless que Google pone a nuestra disposición dentro del abanico de herramientas y recursos de Google Cloud. Nos permite desarrollar funciones y desplegarlas de forma (casi) instantánea, a día de hoy, en los siguientes lenguajes de programación: .NET, Go, Java, Node.js, PHP, Python y Ruby.
¿Cómo funciona exactamente?
En el momento en que queremos desplegar nuestra función, Google la compila y cada vez que la llamamos (mediante algunos de los mecanismos que Google pone a nuestra disposición para hacerlo), el entorno de Cloud Functions la invoca, ésta se ejecuta durante un tiempo máximo y finaliza.
Cloud Functions nos permite configurar nuestras funciones para usar una determinada cantidad de memoria RAM, ajustar la potencia de procesamiento con un número definido de CPUs (o una fracción si la función es muy pequeña), su nivel de concurrencia, el nivel de seguridad, el tipo de disparador (la forma en que se puede invocar nuestra función) y algunos parámetros más.
Esto nos permite crear un abanico de funciones muy flexibles que se adapten a nuestras necesidades sin demasiadas complicaciones.
¿Qué podemos hacer?
Se pueden desarrollar todo tipo de funciones (o aplicaciones) con Cloud Functions desde microservicios a aplicaciones más complejas. Google pone a nuestra disposición una gran variedad de librerías de terceros para complementar el lenguaje de programación que elijamos para el desarrollo. ¿Microservicios? Por supuesto. ¿El Internet de las cosas? Faltaría más. ¿Extracción, transformación y/o carga de datos? ¡Sin problemas!
Si bien no es absolutamente práctico levantar funciones muy grandes (ya que la principal idea detrás de Cloud Functions es lanzar procesos relativamente pequeños de forma repetitiva) no hay demasiados límites en cuanto a lo que se puede hacer.
¿Tiene algún límite?
Aunque hemos comentado que no hay demasiados límites en cuanto a lo que se puede hacer con Cloud Functions, una función tiene un tiempo máximo de ejecución de 540 segundos (9 minutos). Si cualquier proceso se alarga más allá de estos 9 minutos el entorno de Cloud Functions dará por finalizada la ejecución de nuestra función, haya terminado o no.
¿Cuánto te puede costar?
Debemos tener en cuenta la filosofía de Google Cloud: sólo pagas por lo que usas. En función de las opciones de configuración que hayamos usado para crear nuestra función tendrá un coste u otro (a mayor cantidad de memoria RAM o número de CPUs disponibles, entre otros factores, mayor coste).
A esto, además, hay que sumarle el coste que tienen (en caso de que lo tengan) los servicios de los que hagamos uso sean de Google Cloud o sean de proveedores externos (en nuestro caso usaremos BigQuery para almacenar datos, Cloud Functions para la ejecución y la API de Search Console).
Dicho esto, vayamos a lo más interesante:
2. Nuestra primera función con Cloud Functions.
Crear una función con Cloud Functions es bastante sencillo. Para ello, hacemos uso del menú de hamburguesa ubicado en la parte superior izquierda de la pantalla y seleccionamos el submenú marcado como Cloud Functions.

A continuación, hacemos clic en el botón marcado como CREATE FUNCTION.

Entre las diferentes opciones de configuración básica lo primero que debemos hacer es especificar el nombre identificativo de nuestra función. Podemos especificar también la región de Google Cloud en la que se va a ejecutar la función (por defecto suele desplegarse en Estados Unidos) y el entorno en que se va a ejecutar (que, por defecto y en el momento de publicar este artículo, se ejecuta como función de segunda generación).
A continuación debemos definir el tipo de disparador para nuestra función. El disparador por defecto es el de tipo HTTPS (si queremos que nuestra función sea accesible desde una URL) pero podemos escoger otros como Pub/Sub, Firestore u otros. Podemos copiar la URL que aparece justo debajo pues es la URL a la que accederemos para invocar nuestra función.
En este caso, vamos a dejar la opción por defecto (HTTPS) y vamos a seleccionar la opción marcada como permitir invocaciones sin autenticar. Cabe reseñar que esto se debe escoger con cuidado, pues es perfectamente válido a título demostrativo para enseñaros cómo interactuar con vuestra función y es la opción correcta cuando queréis implementar algún tipo de API de acceso público pero, dependiendo de las necesidades y el entorno en que se ejecute la función, puede que os interese más la segunda opción (requerir autenticación) y así limitar su alcance.
Una vez hemos seleccionado el tipo de disparador vamos a ajustar la cantidad de memoria que usará nuestra función en el siguiente apartado:
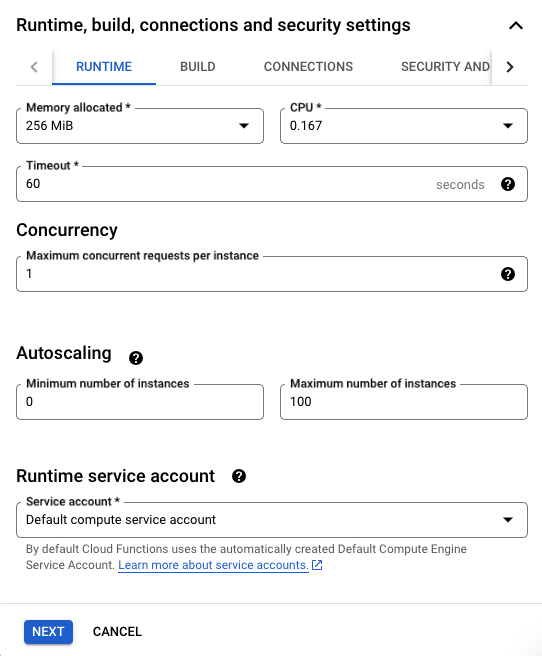
Como es una función sencilla vamos a escoger la mínima cantidad de memoria disponible (128 MB). El resto de opciones no las vamos a tocar.
Si hacemos clic en el botón marcado como NEXT podremos configurar el código para nuestra función.
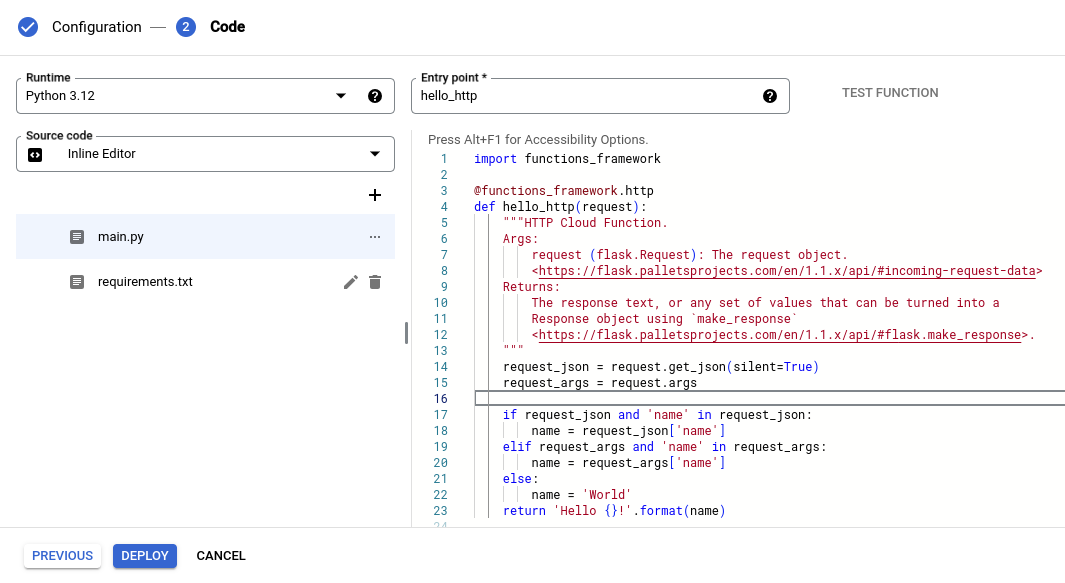
Lo primero que debemos hacer es seleccionar el entorno de ejecución que vamos a usar. En este caso, y usando la primera lista desplegable, seleccionamos Python (cuya última versión disponible en el momento de redactar este artículo es la 3.12).
Tenemos tres opciones para especificar el código de nuestra función: usar el editor en línea (la interfaz que estamos usando en estos momentos), subir un archivo .zip desde nuestro ordenador o hacer lo mismo (subir un archivo .zip) desde Cloud Storage. En este caso, vamos a dejar la opción por defecto (usar el editor en línea).
La última opción a la que debemos prestar atención (pero no modificaremos para este ejemplo) es el nombre del punto de entrada. El punto de entrada es la función o fragmento de código que se ejecutará al invocar nuestra función. En este caso, y habiendo escogido como disparador HTTPS el punto de entrada se llamará, orientativamente, hello_http. Lo dejamos como está.
Sólo nos queda, llegados a este punto, desplegar nuestra función y para ello debemos hacer clic en el botón marcado como DEPLOY. El entorno de Cloud Functions pasará ahora a empaquetar nuestra función y cuando lo haga, y para probarla, tan sólo tenemos que visitar la URL de nuestro disparador. Esto es lo que deberíamos ver:

Y con esto ya tenemos nuestra primera función 😉
3. Qué necesitamos para extraer datos de Search Console.
Extraer datos de Search Console, sea de forma puntual o recurrente, es un proceso bastante rápido y sencillo pero antes de hacerlo necesitamos tres cosas: que tengamos habilitada la API de Search Console entre los servicios que nos brinda Google Cloud, que tengamos acceso a la propiedad de Search Console de la cual queramos extraer datos con los permisos adecuados y que tengamos instalado el cliente de API de Google para el lenguaje de programación que hayamos escogido (en este caso, lo haremos con Python).
API de Search Console
Google Cloud es un entorno en el que, por definición, sólo pagas por lo que usas y, por lo tanto, no viene con la API de Search Console habilitada. Eso es lo primero que debemos hacer. Para ello, hacemos uso del menú de hamburguesa ubicado en la parte superior izquierda de la pantalla y seleccionamos la opción marcada como Enabled APIs & services dentro del submenú marcado como APIs & Services.

A continuación, hacemos clic en el botón marcado como ENABLE APIS AND SERVICES.

Nos aparecerá una caja de búsqueda que usaremos para introducir el término ‘Search Console’. Al presionar la tecla Enter, nos aparecerá el resultado que estamos buscando:
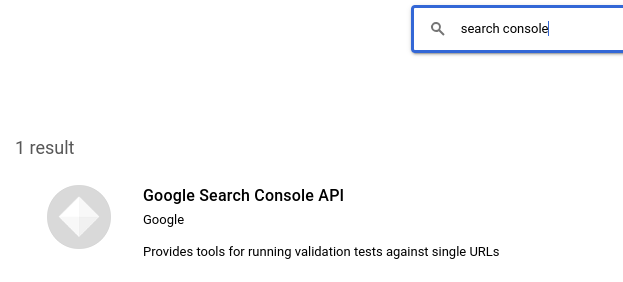
Hacemos clic sobre el resultado de búsqueda y, a continuación, hacemos clic en el botón que nos aparecerá marcado como ENABLE.
Con esto, ya tendremos habilitada la API de Search Console en el entorno de Google Cloud.
Acceso a la propiedad de Search Console
Para poder extraer datos de Search Console de una propiedad determinada de manera programática necesitamos un usuario al que dar acceso a dicha propiedad. En este caso, vamos a usar la cuenta de servicio que creamos al principio y para la cual anotamos la dirección de correo electrónico asociada a dicha cuenta de servicio. Para ello, y teniendo seleccionada una propiedad en la interfaz web de Search Console, hacemos clic en la opción marcada como Ajustes.
Una vez se nos presenten las diferentes opciones dentro del menú de ajustes, seleccionaremos la opción marcada como Usuarios y permisos.
Cabe reseñar que sólo tendremos acceso a esta opción si el usuario con el que accedemos a la interfaz web de Search Console tiene los permisos adecuados. En caso contrario tendremos que revisarlos (o pedir que lo hagan por nosotros, en caso de que la propiedad pertenezca a un tercero).
A continuación, hacemos clic en el botón marcado como AÑADIR USUARIO.
Introduciremos, en el formulario que veremos a continuación, la dirección de correo electrónico asociada a la cuenta de servicio que anotamos al principio y seleccionamos los permisos necesarios. En este caso concreto, y dado que sólo vamos a extraer datos, los permisos necesarios son los mínimos aplicables. Por lo tanto, escogeremos la opción marcada como Restringido, que nos confiere acceso de lectura a los datos (todo lo que necesitamos para esta guía).
Para finalizar haremos clic en el botón marcado como AÑADIR y con esto ya tendremos acceso concedido a la cuenta de servicio para extraer datos de Search Console.
Cliente de API para Python
Para extraer los datos de Search Console usamos el cliente oficial de Google para Python, cuyo identificador en PyPi (el repositorio oficial de terceros para paquetes de Python) es google-api-python-client. Podemos instalar la librería mediante el comando pip o incluyendo la librería en el archivo requirements.txt y, nuevamente, instalando (o actualizando) las dependencias con el comando pip.
4. Cómo extraer datos de Search Console.
Ahora que tenemos todo lo necesario para poder realizar la extracción de datos (las credenciales adecuadas en Google Cloud, la API de Search Console habilitada, acceso a la propiedad de Search Console de la que queremos extraer datos, el cliente de API adecuado y unas mínimas nociones de Cloud Functions) vamos a realizar una extracción de datos sencilla y a volcar dichos datos a la salida en formato CSV (para que podamos descargarlos en formato de archivo o consumirlos, por ejemplo, desde otro proceso externo).
Estructura de archivos
En nuestra Cloud Function tenemos tres archivos: main.py (que es donde está el código de nuestra función), requirements.txt (donde especificaremos las dependencias de software de nuestra función) y el archivo .json con las credenciales de la cuenta de servicio que mencionamos anteriormente, quedando así:
Dependencias de software
En el archivo requirements.txt pondremos las dos dependencias necesarias para que funcione el código de extracción de Search Console, que son las siguientes:
- google-api-python-client (el cliente de API oficial de Google para Python)
- oauth2client (para acceder a recursos protegidos con OAuth 2.0)
El código de nuestro extractor de datos de Search Console
Y, finalmente, el código para nuestro extractor de datos. Primero las importaciones y definiciones básicas:
# aliases and/or imports
from collections import OrderedDict
from datetime import datetime, timedelta
from googleapiclient.discovery import build
from oauth2client.service_account import ServiceAccountCredentials
from time import sleep
# row limit (per API request)
row_limit = 10000
# service account (.json) file
service_account_file = ""
# initialize the Search Console client
api_client = build("webmasters", "v3", credentials=ServiceAccountCredentials.from_json_keyfile_name(service_account_file, ["https://www.googleapis.com/auth/webmasters.readonly"]))
A continuación definimos la función con la que vamos a extraer los datos:
def extract(domain: str,
date: str,
dimensions: list,
aggregation_type: str,
search_type: str) -> list:
"""
:param domain: the Search Console domain
:param date: the extraction date (in YYYY-MM-DD format)
:param dimensions: the dimensions we want to extract
:param aggregation_type: the aggregation type (byPage or byProperty)
:param search_type: the search type (image, news, video, web)
"""
if len(domain) == 0:
raise Exception("invalid domain")
if len(dimensions) == 0:
raise Exception("no dimensions provided")
if (
len(aggregation_type) == 0
or aggregation_type not in ["byPage", "byProperty"]
):
raise Exception("invalid aggregation type")
if (
len(search_type) == 0
or search_type not in ["image", "news", "video", "web"]
):
raise Exception("invalid search type")
page_index = 0
rows = []
while True:
response = api_client.searchanalytics().query(
body={
"startDate": date,
"endDate": date,
"dimensions": dimensions,
"dimensionFilterGroups": [],
"aggregationType": aggregation_type,
"searchType": search_type,
"rowLimit": row_limit,
"startRow": page_index
},
siteUrl=domain
).execute()
sleep(5)
if "rows" not in response:
break
else:
metrics_keys = list(response["rows"][0].keys())[1:]
row_count = len(response["rows"])
row_keys = dimensions + metrics_keys
for row in response["rows"]:
temp_row = OrderedDict()
for key in dimensions:
temp_row[key] = row["keys"][dimensions.index(key)]
for key in row_keys:
if key in metrics_keys:
temp_row[key] = int(row[key]) if key in ["clicks", "impressions"] else row[key]
rows.append(list(temp_row.values()))
if row_count < row_limit:
break
else:
page_index += row_limit
return rows
Y, finalmente, la función que se ejecutará cuando se invoque nuestra función:
def cloud_function(request):
"""
main entry point
:param request: an instance of the Request class
"""
aggregation_type = "byPage"
date = (datetime.now() - timedelta(3)).strftime("%Y-%m-%d")
dimensions = ["date", "query", "page", "device", "country"]
domain = ""
search_type = "web"
rows = extract(domain, date, dimensions, aggregation_type, search_type)
if len(rows) > 0:
print("Content-Type: text/csv")
return "\r\n".join(list(map(
lambda x: ",".join(list(map(
lambda y: "\"%s\"" % y, x
))), rows
))), 200
else:
return f"no rows for {date}", 404
Esta función extraerá los datos de Search Console para la propiedad que hayamos definido en la variable domain de hace tres días. Esto lo hacemos así porque los datos de Search Console pueden tardar hasta 48 horas en consolidarse y, de esta manera, nos aseguramos de que el dato es final. Cabe reseñar que también debemos especificar el valor de la variable service_account_file porque es el archivo .json con las credenciales que guardamos al principio de este artículo. Si vuestro archivo se llama credentials.json (por poner un ejemplo) entonces el valor de la variable debe ser justo ese.
El resultado final, en caso de que haya datos, los mostrará en pantalla en formato CSV y con eso podéis guardarlos como archivo o incluso consumirlos desde un servicio externo para incluir estos datos en otro proceso de datos.
Las posibilidades son infinitas 😆





